云开体育这一引擎却被限度在一条忐忑的乡间小径上-云开app·Kaiyun下载官方网站-登录入口

 智东西云开体育
智东西云开体育
智东西11月5日报说念,近日,腾讯微信AI团队发布的一篇论文在国外AI圈激勉庸碌情切。论文提议了一种名为“一语气自归来谈话模子(CALM)”的新颖架构。与传统Transformer比较,CALM径直将老练大模子所用的筹办量减少了44%,推理时的筹办量也减少了34%。
CALM的中枢逻辑是,将一语气的K个token压缩成一个语义向量,并在生成时径直瞻望“下一个向量”而非“下一个token”。假定K=4,那么蓝本需要缓缓生成4次的践诺,当今只需1步即可完成,使其能在一次生成中输出更多信息,大幅提高遵守。
这项探究的联系参议在外交媒体平台X的阅读量累计依然高出100万次,在褒贬区引起热议。
辅导词共享网站godofprompt.ai的结伴首创东说念主Robert Youssef以为,CALM大约等于AI鸿沟下一次大的范式编削,透顶颠覆了通盘大谈话模子赖以构建的“下一个token瞻望”范式,让大模子不再逐字念念考,而所以想法为单元进行念念考,真实弗成念念议。这一顺序淌若能顺利延伸,那么现存的LLM都将过期。

还有多位网友以为CALM提议的主见值得探讨,但关节是需要在更大限制的Scaling经由中获取考据。

然而,也有东说念主质疑CALM的远景。这位网友称,CALM仅仅杨立昆的一个老旧想法,老练不自如,基础很薄弱,且无法延伸,是一种“有颓势的决策”。

CALM论文的作家均在微信AI团队任职,第一作家邵晨泽曾在中科院筹办所智能信息处理实验室完成博士学业。这篇论文的其他作家包括Darren Li、Fandong Meng和Jie Zhou,其中,Darren Li是清华大学求真学院的在读学生。为便捷后续探究,探究使用的预老练Autoencoder以及CALM的查验点均可供下载。

论文地址:
https://arxiv.org/abs/2510.27688
样子主页:
https://github.com/shaochenze/calm?tab=readme-ov-file
一、性能并列同量级Transformer,老练筹办量减少44%那么,在与Transformer的对决中,CALM究竟发达出了何种上风?
在评估两者的性能前,CALM团队最初需要打造适合的评估器具。以前业内用来揣度谈话模子瞻望质地的一个主张是困惑度(Perplexity),直不雅地说,它示意模子在面临信得过谈话数据时“有多困惑”——困惑度越低,证实模子越自信、瞻望越准确。
困惑度评估并不适用于CALM的架构。作家因此提议新的评价体系——BrierLM主张。这一主张源于经典的Brier Score,由征象学家Glenn W. Brier在1950年提议,用来评估天气预告的横暴。
BrierLM通过组合不同n-gram的Brier得分,提供了一个调处的、可比较的谈话建模主张。它垄断模子采样闭幕即可无偏意象瞻望质地,既能揣度准确性,又能处理过度细则性。
实考据明,BrierLM与交叉熵险些线性联系,可四肢困惑度的替代品,并适用于其他隐式生成模子。

CALM团队使用The Pile语料老练了多款CALM架构的模子,然后用WikiText-103数据集来测试模子的性能。
老练时,CALM团队离别打造了不同参数目的模子,离别为0.371B参数目的CALM-M、0.735B参数目的CALM-L和1.82B参数目的CALM-XL。
当K=4,也等于每个一语气向量对应4个原始token时,CALM-M的性能略逊于0.281B参数目的Transformer-S模子,但CALM-M的老练筹办量比Transformer-S少44%,推理筹办量少34%,展现出更好的算力-性能均衡。跟着模子变大,性能也自如提高,就像平时Transformer同样。

CALM团队还探究了语义带宽K的作用。跟着语义带宽K增大,筹办需求线性着落,而但性能着落并不明白。
当K从1变为2时,模子所需的老练算力大幅减少50%傍边;当K=4时,CALM达成了遵守与性能的较好均衡;K=8时,其性能出现一定下滑。
CALM团队以为这是模子尺寸导致的。以后,跟着模子尺寸的提高,CALM架构大约不错一次性瞻望更多token,从更大的语义带宽中受益。

CALM的作家们还比较了不同生成头的性能。能量模子单步生成性能最高,况兼不需要迭代采样,一次就能生成闭幕。扩散与流匹配模子虽可行,但要么性能欠安,要么代价崇高。

那么,CALM究竟为何要进行从“瞻望token”到“瞻望向量”的强大编削呢?这一滑变,又是如何让CALM以更低的算力需求,达成并列Transformer的生成恶果?
CALM的第一作家邵晨泽在其撰写的博客中,讲解了打造CALM的原因。当代大谈话模子好比一个“法拉利级”的引擎——它领稀有千亿参数,能够聚首语义、实践复杂推理、生成高质地文本与代码。
然而,这一引擎却被限度在一条忐忑的乡间小径上,永久只可卡在第一档。这条小径等于自归来生成机制:模子一次只可瞻望一个冲破token,无论引擎多强,朦拢量都会受到限度,这导致了模子推理速率慢、筹办资本高级问题。
以前,东说念主们试图通过扩大基本单元来“拓宽说念路”。从字符级到子词级(subword token)的变化,如实提高了遵守。
但如今,这条旅途已涉及“冲破token的物理极限”:在一个典型的32K词表中,每个生成顺序的语义带宽约为15位,要想将带宽翻倍,词表限制必须指数级增长——这使得模子在筹办上险些弗成行。换句话说,冲破token的Scaling依然碰壁了。
淌若冲破token是瓶颈,那么咱们就需要一种具有可延伸语义带宽的新式文本单元。CALM代表从冲破到一语气的变化,其中枢念念想等于让模子不再瞻望下一个token,而是瞻望下一个向量——一个压缩了一语气K个token的语义信息。
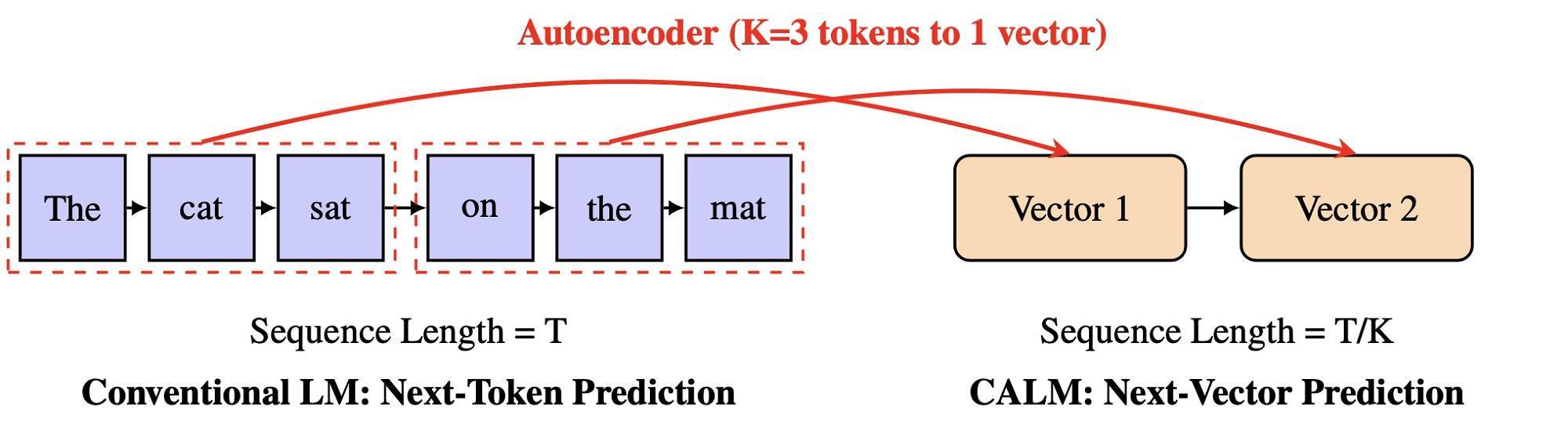
这一改变特地于为大模子开辟了一条多车说念的高速公路——每次生成能捎带更多语义,显耀减少自归来步数,从而大幅提高遵守。
CALM的第一步是修复一个高保真自编码器(Autoencoder),在冲破token与一语气向量之间修复双向映射。
编码器的作用是将一段K个token压缩为一个一语气向量,而解码器从该向量中重建出原始tokens。
通过交叉熵耗费老练后,该模子能以99.9%的精度重构文本片断。论文指出,这是可行的:一个浮点向量的比特容量远高于一个冲破token,足以存储多倍的信息。
然而,高精度重构并不代表模子的自如性。若向量空间过于“脆弱”,轻细噪声就可能使解码器输出都备不同的文本。为此,作家引入了三项关节编削:
变分正则化(VAE):令编码器输出高斯漫步,使潜空间更平滑;
KL编著(KL Clipping):防患潜变量塌缩到无效维度;
双重Dropout:对输入与潜向量加入噪声,迫使模子学习冗余且自如的表征。
闭幕是一个既紧凑又正经的一语气语义示意:当K=4、潜向量维度为128时,模子在加入约0.3方差高斯噪声的情况下,仍能保合手99.9%的重构精度。
这一语义压缩器为CALM奠定了坚实基础——让谈话不错在一个可一语气建模、可容错的向量空间中流动。
三、 怎样让模子瞻望下一个向量?靠“无似然建模”有了向量化的语义序列,谈话建模任务酿成了瞻望下一个一语气向量。然而,如何熏陶模子进行下一个向量瞻望,又成了新的挑战。
如今,险些通盘主流大模子都取舍最大似然老练(Maximum Likelihood Estimation)——即通过softmax筹办出“每个token出现的概率”,并最大化老练数据的似然值的作念法。
这么的老练模样条款模子能在一个冲破的词表中明确地为每个token给出概率漫步,但在一语气向量空间中,莫得有限词表,softmax无法界说概率漫步。
因此,CALM废弃了最大似然老练,转而取舍无似然建模(likelihood-free modeling)。这种顺序不再条款模子显式筹办概率,改用障碍标的函数,让模子学会生成与数据漫步相似的样本。
通俗来说,模子不再告诉你“这个词的概率是若干”,而是径直生成一个向量,让它尽可能接近信得过的语义向量漫步。
CALM的作家团队尝试了多种无似然顺序(如 Diffusion、Flow Matching),但最终提议并考据了最优决策——基于能量评分(Energy Score)的生成头(generative head)。

▲CALM的模子架构
这一世成头招揽Transformer的遮蔽景色和一个当场噪声向量四肢输入,在一语气空间中瞻望下一个语义向量。通过优化能量得分,模子能够在不筹办显式概率的情况下,学会生成既各样又合适语义规则的向量序列。
能量得分是一种严格正确的评分规矩,不依赖概率密度,而以样本间距离揣度瞻望漫步的横暴。它同期均衡两种标的:
(1)各样性项处理过度自信、饱读吹各样化生成;
(2)保真项奖励瞻望与信得过向量接近。
模子通过最大化能量得分,使其隐式漫步靠近信得过数据漫步。为了达成高效老练,作家取舍蒙特卡洛意象,仅需少量样本即可获取无偏梯度。
这种顺序带来了两大上风。最初,不同于扩散模子需上百次采样,Energy Head一步即可生成下一个向量;其次,这一顺序的通用性强,只需能采样即可老练,无需显式概率公式。
在推理时,CALM将瞻望向量传入预老练的解码器,回应出冲破token,再经轻量MLP压缩输入到Transformer,达成无缺的自归来轮回。
在传统的LLM中,调度温度(temperature)是限度生成“创造力”的关节技能。模子在生成时会输出一组logits——也等于每个候选token的未归一化得分。通过将这些logits除以温度参数T,再经过softmax,就能得到新的概率漫步。
然而,CALM莫得logits。因此,其背后团队提议了基于间隔采样与Bernoulli Factory表面的全新算法:
(1)当温度T=1/n时,只需抽取n个样本,若全相通则罗致;
(2)对率性T,可领悟为整数与极少部分并通过二阶段采样达成。
CALM团队还联想了批量雷同算法,可显耀提高遵守且在表面上无偏差。这使得CALM过甚他隐式模子能够像平时大谈话模子同样达成可控生成。
结语:大模子探索Scaling新旅途将来,CALM的作家团队霸术无间在架构和算法方面进行更多优化,包括联想更优的自编码器、开垦更刚烈的架构以及提议更轻量级的采样工夫。
他们还但愿探索CALM的Scaling特色,考据一大关节假定:更大模子是否具备复古更高语义带宽的必需容量。CALM的作家们以为,“语义带宽K”已成为继参数限制与数据量之后云开体育,大模子性能的第三个可延伸维度。
